
Abstract:
We present an interactive approach to semantic modeling of indoor scenes with a consumer-level RGBD camera. Using our approach, the user first takes an RGBD image of an indoor scene, which is automatically segmented into a set of regions with semantic labels. If the segmentation is not satisfactory, the user can draw some strokes to guide the algorithm to achieve better results. After the segmentation is finished, the depth data of each semantic region is used to retrieve a matching 3D model from a database. Each model is then transformed according to the image depth to yield the scene. For large scenes where a single image can only cover one part of the scene, the user can take multiple images to construct other parts of the scene. The 3D models built for all images are then transformed and unified into a complete scene. We demonstrate the efficiency and robustness of our approach by modeling several real-world scenes.
Teaser caption: Lab scene. (a) Captured images (Only RGB data are shown). (b) Reconstruction result. Only 6 RGBD images captured by Microsoft Kinect camera are enough for our system to reconstruct its prototype scene with 20 objects of semantic labels (eight monitors are not numbered to avoid possible clutter). The numbers in white indicate the correspondence between objects in the image and their reconstruction results and the overall modeling time of this lab scene is less than 18 minutes.
System Pipeline:
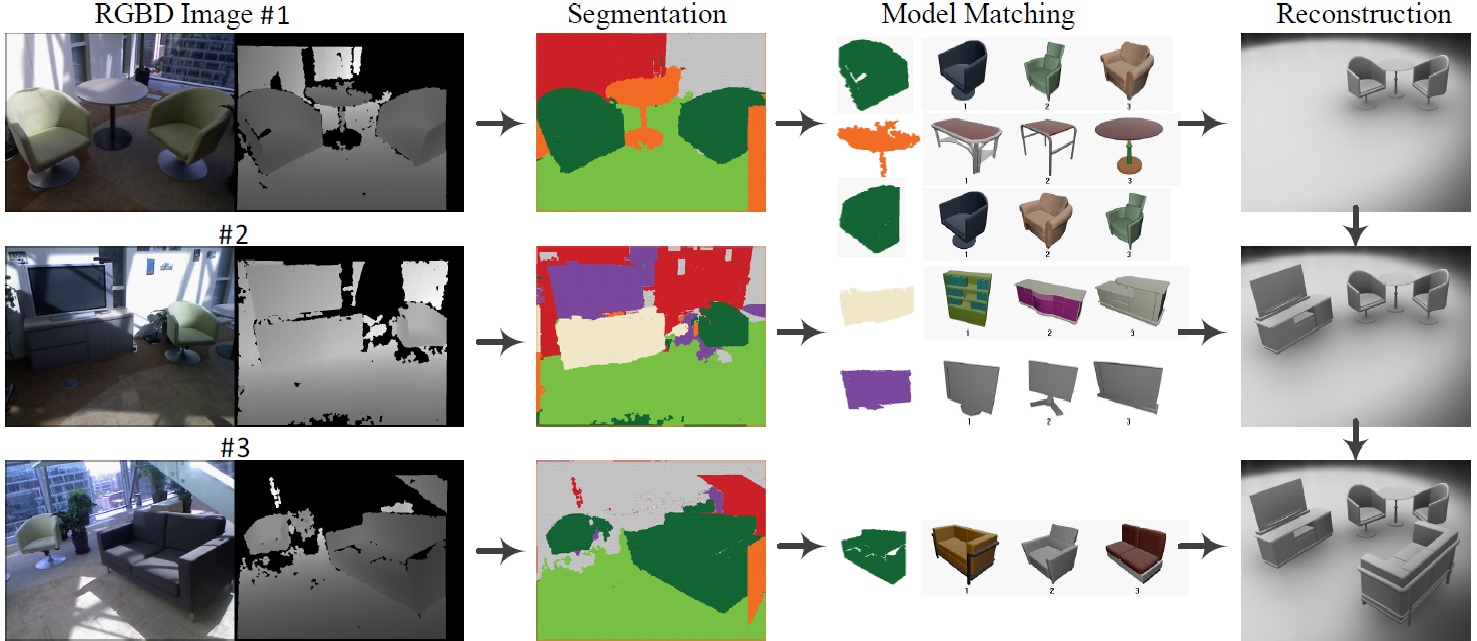 |
Video: (download)
Acknowledgements:
Bibtex:
@article{Shao:2012:IAS:2366145.2366155,
author = {Shao, Tianjia and Xu, Weiwei and Zhou, Kun and Wang, Jingdong and Li, Dongping and Guo, Baining},
title = {An Interactive Approach to Semantic Modeling of Indoor Scenes with an RGBD Camera},
journal = {ACM Trans. Graph.},
issue_date = {November 2012},
volume = {31},
number = {6},
month = nov,
year = {2012},
issn = {0730-0301},
pages = {136:1--136:11},
articleno = {136},
numpages = {11},
url = {http://doi.acm.org/10.1145/2366145.2366155},
doi = {10.1145/2366145.2366155},
acmid = {2366155},
publisher = {ACM},
address = {New York, NY, USA},
keywords = {depth images, indoor scene, labeling, random regress forest, segmentation},
}
|
|
